Other articles in this series:
Introduction
With the proliferation of data – collecting and storing it, sharing it, mining it for gains – a basic question goes unanswered: is this data even good? The quality of data is of utmost concern because you can’t do meaningful analysis on data which you can’t trust. Here in Veracity, we are trying to address this is very concern. This is a 3 part series, going all the way from concept to a working implementation using DLT (Distributed Ledger Technology).
Side note, Veracity is designed to help companies unlock, qualify, combine and prepare data for analytics and benchmarking. It helps data providers to easily onboard data to the platform, and enable data consumers to access and mine value. The data can be from various sources, such as sensors and edge devices, production systems, historical databases and human inputs. Data is generated, transferred, processed and stored, from one system to another system, one company to another company.
Veracity is by DNV GL, and DNV GL has held a strong brand for more than 150 years as being a trusted 3rd party, yet it is still pretty common to hear questions from data consumers such as:
1. Can I trust the data I got from Veracity?
2. How was the data collected and processed?

In order to answer these questions and bring more transparency to the data process lifecycle, we must address both data integrity and data lineage. Both Data integrity and data lineage are the foundation of trust.

In this series of articles, we are going to look at different challenges of data integrity and lineage, and evolve the solution. (Note that integrity is one of the 3 parts of CIA triad: confidentiality, integrity and availability, but we will not cover confidentiality and availability in this series.)
Data Integrity
Let’s start with a basic example:
Alice sends messages (ie. files) to Bob. The messages were sent via an insecure channel, such as http-based data transfer, ftp, file share or even an USB stick.

Basic requirements:
There are 2 basic requirements for any data communication:
- The messages were not tampered by man-in-the-middle.
- The messages that Bob received, are indeed from Alice.
There are mainly 2 ways to ensure this: encryption and/or hashing. (A nice articles for comparing hashing and encryption can be found at here.)
Iteration #1
In iteration 1 we focus on solving requirement #1: The messages were not tampered by man-in-the-middle. We either use encryption or hashing.
1.1 Using Encryption (with symmetric or asymmetric key)

- Pro: Encryption is pretty straight forward: Either use symmetric or asymmetric key, Alice and Bob can encrypt and decrypt messages without worrying data tampering.
- Con: However, this requires key management, both for Alice and Bob.
1.2 Using Hashing

- Pro: Does not require key management for both Alice and Bob.
- Con: With hashing, it requires an additional data flow for passing hash values from Alice to Bob. It actually requires the same security mechanism as the normal data flow.
We can address the Con by introducing a trusted area for Alice. For example, Alice also publishes the hash values of the messages on https://alice.com. Bob can verify the message by compare the hash values. It is also OK to make the trusted area public, as hash value is irreversible - nobody can obtain the data by using the hash value, they can only check the message integrity.
This solution is sort of adding a secured “safeguard” track on the side, to help verifying the data flowing in the insecure channel.

- Pro: Does not require key management for both Alice and Bob. Solved the problem for protecting hash value data flow.
Iteration #2
In iteration #2, in additional to requirement #1, we also need to also fulfill requirement #2: The messages that Bob received, are indeed from Alice.
2.1 Using Encryption (with Asymmetric key)
This normally requires asymmetric encryption: Alice encrypts the message with her private key, and Bob decrypts it with Alice’s public key. Therefore, Bob is confident that Alice is the message author.

2.2 Using Hashing (with a trusted area), same as iteration #1
Hashing solution with a trusted area can also meet this requirement, simply counting on ONLY Alice can write into the trusted area.
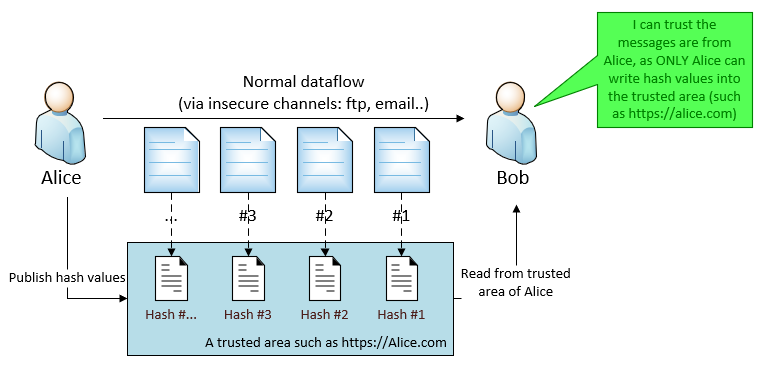
Conclusion of iteration #1 and #2
For ensuring the basic requirements, both solutions work:
- Using Encryption (with asymmetric key), and
- Using Hashing (with trusted area)
Challenge of accountability and non-repudiation
Now, an interesting real challenge: Once Alice sends out a message, she can neither deny the message was sent, the message’s origin nor the original content. In another word, the challenge is about accountability and non-repudiation.
It can be explained by the following example:

(click to enlarge the picture)
At this point, these above solutions that we have so far cannot help Bob. For example, Alice can replace both the message and the hash value in https://alice.com.

With encryption solution, although Bob can prove the buggy version of message #2 is from Alice, but he cannot prove that Alice sent out the buggy version on Monday.
**In general, Bob (and we) need an immutable history that provides immutable traceability of data, such as when and what data was sent and processed. **
It definitely helps provides data consumers like Bob, but there are benefits for well-behaved data providers as well: By offering the immutable history, it increases the data’s acceptance from that providers, as well as increases value and trust of the provider.
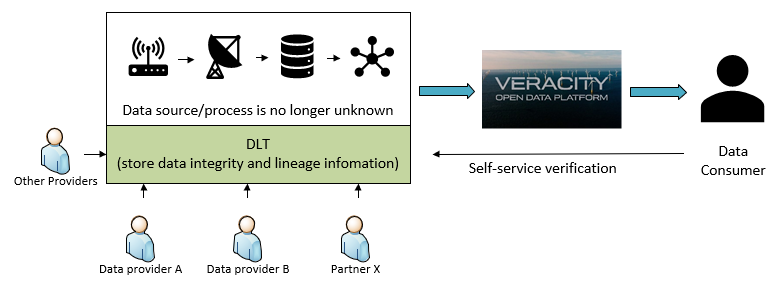
Iteration #3 - introduce DLT as immutable history
Distributed Ledger Technology (DLT) shows its potential capacity to become a natural place for storing data integrity and data lineage information, as it has the following key features:
- Data Immutability
As the data is replicated in all nodes in the DLT network, it means that the data is immutable, even the author cannot modify his/her records once it is confirmed in ledgers. - Decentralized
The ledger network is decentralized, means all participators have the same copy of the data, including Alice and Bob. There is not a central authority can control the whole network and the records in it. - Built-in authentication
In order to send data to the ledger, the author must use his/her private key. It provides the built-in authentication for identifying who is the author of the data/transaction.
3.1 Encrypted message within DLT
As DLT does support built-authentication, there is no need to use asymmetric(public/private) key for identity purpose. You can still use symmetric key for protecting the message from unauthorized access.
However, there are some limitations for using DLT as the secured channel. The biggest one is the size limitation of the message. For example, bitcoin size limitation is 1 MB and ethereum is of similar size. For lots of the cases, this limitation is show-stopper.
Therefore, the hashing solution with DLT is more realizable. See below.
3.2 Hashing with DLT

By only putting hash value of the messages into DLT, we can solve the size limitation issue.
It means:
- Alice continues to send messages via the insecure channels.
- Meanwhile, Alice sends the hash values of the message into DLT.
- All hash values that Alice sent to DLT, is signed by Alice’s private key. So everyone knows it was author (Alice), the original message’s digest and when the data was sent (timestamp).
- Once Bob received the message via insecure channel, he can
- Find the transaction that contains the hash value for that message from DLT
- By check the transaction’s metadata, Bob can check the author and timestamp.
- By check the hash value from that transaction, Bob can verify the message content is not tampered.
- Also, it is impossible for Alice want to replace an old hash value. So Bob is protected from an immutable history.
Data Lineage
The goal of data lineage is to track data over its entire lifecycle, to gain a better understanding of what happens to data as it moves through the course of its life. It increases trust and acceptance of result of data process. It also helps to trace errors back to the root cause, and comply with laws and regulations. You can easily compare this with the traditional supply chain of raw materials in manufacturing industry and/or logistic industry.
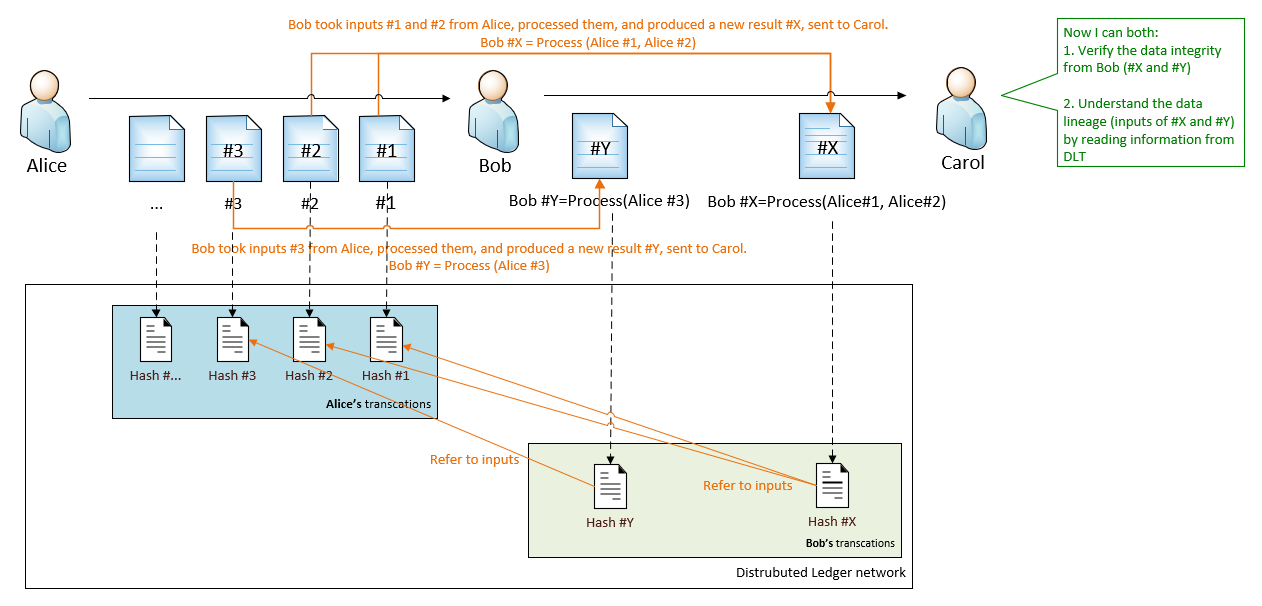
For example, Bob is running a data process. This process takes inputs from Alice, then produces results. The results are sent to Carol.
- Bob produces result #X, based on inputs from Alice #1 and #2.
- Bob produces result #Y, based on input from Alice #3.

For Carol, some typical questions are:
- What inputs Bob used for producing the results #X and #Y?
- Do these inputs also have another input? If yes, what are they?
- Is there a way to have to full picture of the whole data process lifecycle, without asking Bob (and every upstream) in the supply chain?
Data Lineage with DLT
Now we continue building on top of the Hashing solution with DLT. Whenever a data provider (for example, Bob) sends out data, he writes into DLT that contains:
- Hash value, which will be used for data integrity verification (same as before), and
- If the data has inputs, the reference to the input are also stored into DLT
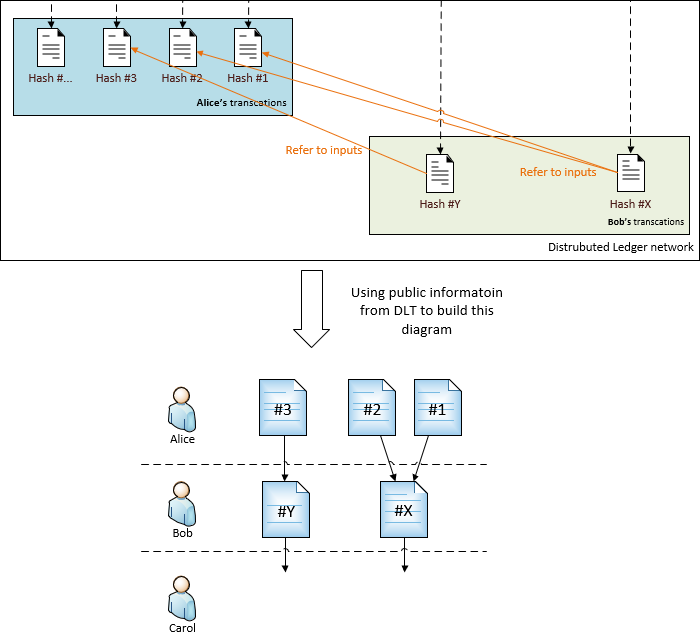
It means that the DLT contains the end-to-end data lifecycle information. Carol (and anyone else) only need to query the public information from DLT to build the lineage diagram.
With this solution, Carol can:
- Gain the knowledge that that Bob is using data from Alice as inputs, without asking Bob.
- Verify the data integrity for both Alice and Bob, even Carol does not directly consume the data from Alice.
- Data integrity and data lineage information is immutable.
Extra protection for data processor
In above process, Bob is a data processor that accepts inputs from Alice (upstream), process it and send results to Carol (downstream).
This solution also provides an extra protection for Bob. For example, if Bob sent a data to Carol based on an incorrect input from Alice, Bob can simply explain that the root cause of the error is not on him but Alice, and Alice cannot deny that.
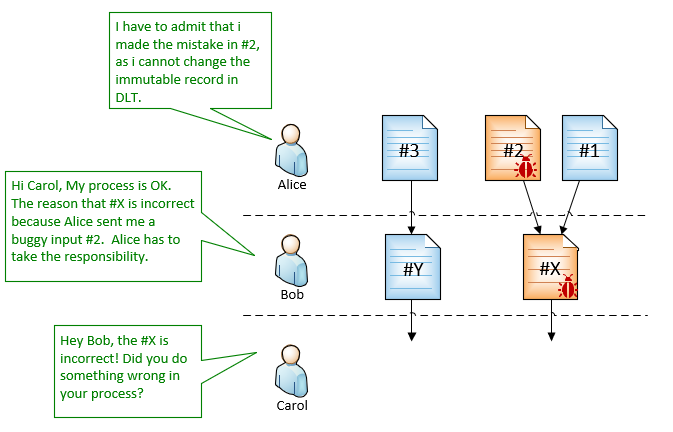
This also means this solution can greatly simplifying the ability to trace errors back to the root cause, even the whole process includes different parties/organizations.
Conclusion
Now we have went through different requirements and evolved solutions accordingly. At the end we believe the hashing solution with DLT can solve both data integrity and data lineage challenges. If the eco-system (data source, data processors and platform) can follows the same design, it will significantly increase the trust of data consumers as well as build more value into the data.
In the next article, we will look at this solution in action, by using IOTA as the selected DLT.
Other articles in this series: