Other articles in this series:
In my previous article, we discussed different approaches for solving the data integrity and lineage challenges, and concluded that the “Hashing with DLT“ solution is the direction we will move forward. In this article, we will have deep dive into it. Please not that Veracity’s work on data integrity and data lineage is testing many technologies in parallel. We utilise and test proven centralized technologies as well as new distributed ledger technologies like Tangle and Blockchain. This article series uses the IOTA Tangle as the distributed ledger technology. The use cases described can be solved with other technologies. This article does not necessarily reflect the technologies used in Veracity production environments.
Which DLT to select?
As Veracity is part of an Open Industry Ecosystem we have focused our data integrity and data lineage work using public DLT and open sourced technologies. We believe that to succeed with providing transparency from the user to the origin of data many technology vendors must collaborate around common standards and technologies. The organizational setup and philosophies for some of the public distributed ledgers provides the right environment to learn and develop fast with an adaptive ecosystem.

There are many public DLT platforms nowadays, but not all of them (such as Bitcoin and Ethereum) are suitable for Big Data or IoT scenarios, such as:
- We are tracking logical data entities (bits, files or data streams) instead of physical entities (coal, car parts or packages).
- The granularity of data has much more detailed scale in IoT and the Big Data world. One example is, tracking every single piece of coal from a carrier ship sounds crazy, but tracking every data signal from thousands of sensors from the very same ship is quite common.
- We need to use DLT to handle large volume of transactions within a short time period (e.g. send 1000 data points from one device to another device per minute)
- We need to use DLT to store large amount of data (e.g. data integrity information of thousands of sensors)
- High transaction fees will weaken the business case.
IOTA - the selected DTL for exploring
We have been watching closely at the technology evolution of distributed ledgers and exploring different possibilities. Currently we are exploring IOTA, which is a new type of DLT that foundationally different from other blockchain-based technologies. The high-level comparison can be found at IOTA FAQs, question “How is IOTA different from Blockchain?”
We decide to test our solution on top of IOTA, due to the following key features that IOTA offers:
- Promise of higher performance and scalability: Thanks to tangle data structure.
- Zero Transaction Fee: Machine to Machine micropayments. This way machines can pay each other for certain services and resources.
This is not an article of introducing IOTA, but you can learn more from https://www.iota.org
MAM protocol from IOTA
In addition, IOTA provides a protocol named Masked Authenticated Messaging (MAM) that easily fit into our solution. MAM provides an abstract data structure layer (channels) on top of regular transactions. In our solution, all read and write data into DLT (tangle) is around MAM channels. Check the article appendix for more resources of MAM.
- One person or application creates a private seed. The seed shall be considered as a private key, and not be shared with others.
- One seed can create one unique MAM channel in IOTA tangle that can store messages.
- Messages contain data such as json object.
- The private seed ensures that only the seed owner is authorized to write messages in the channel. Therefore the origin of the messages is trusted by others.
- Once the message was written into channel, the message is replicated and stored in all nodes in DLT. It means the message is immutable.
- Once you know a MAM address in the channel, you can go through all addresses (and fetch their messages) that follows the known address, such as root address -> address 1 -> address 2 -> address 3 -> address N…
- The message can be fetched from channels by using the MAM address.
Therefore, Alice can publish the hash values like the following diagram
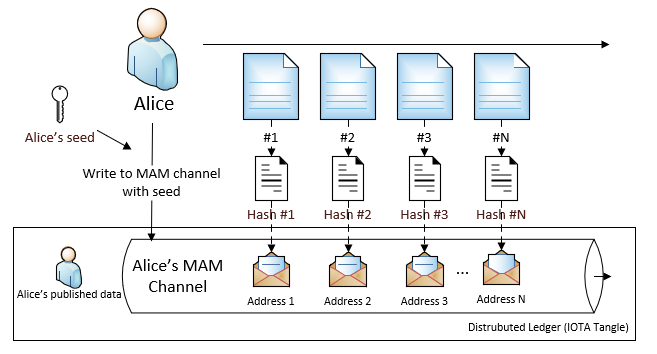
In above case, Alice creates one channel with her private seed. Then she sends messages into this channel, one address has one message.
Sample code for sending MAM message to channel
There is a sample code for sending message into IOTA tangle at https://github.com/linkcd/IOTAPoC/blob/master/tangleWriter.js from my repository.
This code simply:
- Generates a random seed and create a public MAM channel
- Accepts inputs from keyboard and send it to tangle as json format
- Once the message was sent do tangle, anyone can query the tangle and read it from the public channel. But none can change it since it is immutable. You can read the MAM message by using a good tool https://thetangle.org/mam.

Design principles and conceptual entities
First, let’s agree some design principles and conceptual entities
1. Self-service verification process
The verification process of both data integrity and data lineage should be self-service. It means that all verification information should be available to public. Data provider should not be bothered by this process.
(Technically it is possible to have permission control of the verification process, by using private or restricted MAM channels, it means that data provider has to response to the ad-hoc verification requests)
2. Data lineage verification is an add-on on the side of the main data-flow
It means that data lineage will not impact the existing data flow, nor become a bottleneck.
3. Conceptual entities
3.1 Data Source
- A sensor, person or application that generates data package(s)
- Has 0 or more inputs (upstream data source)
- Has 1 or more outputs (downstream data source)
- A company can have more than one data sources
3.2 Data Package
An atomic unit in data flow from one data source to another data source. For example:
- A data point (23 degree at 10:30am), or
- A file (json, xml)
- Files (1.json, 2.json…10.json…)
- Data rows in a database (row #1 to row #10 in table “employee”)
3.3 Data Package Id
The unique ID of a data package in the scope of a data source. A typical data package ID is a number, a GUID or a time-stamp.
3.4 Data Stream
Data stream is data package series from the same data source. It contains more than one packages and their IDs.
Deep dive #1: Data integrity
Goal: Data consumers can verify the integrity of data packages from a data source.
Overview of data integrity workflow
The high level overview of data integrity workflow is as following:

Step 1. Data source announces its MAM channel root address, for publishing integrity information
Data source creates a MAM public channel by using its private seed, then share the root address of this channel with public. It can be done, for instance, via data source’s web site.
Side Note: Why publish only root address, not all individual addresses per each package
The data source can, of course, publish all individual addresses for all messages, but it will be too many. As long as consumers have the channel root address, they can go through all addresses from the root, to find the specific address/message to verify. See step 5.
Step 2. Decide your integrity information content
In order to allow the consumer to verify the integrity, data source need to provide enough information to make it possible. Therefore, you need to decide what information should be stored in the tangle as json object.
Mandatory fields
All object must have the following core fields. All of them are mandatory.
1 | { |
| Field | Description | Example |
|---|---|---|
| datapackageId | The package ID is used for querying the data lineage info from the channel. Data source decides the ID format, such as integer or GUID. Different channels can have the same package ID. | “123456” |
| wayofProof | Information about how to verify the integrity based on valueOfProof. For example, it explains the used hash algorithms (SHA1 or SHA2 or others), or it simply copied the data package content into field valueOfProof. | “SHA256(packageId, data-content)” |
| valueOfProof | The value of the proof, such as hash value, or the copy of the data content in clear text. | (hash value or data itself) |
Example
An application (aka data source) generates big csv files and pass to the downstream (aka data consumer). All csv files have a unique file name. The application decides to hash the file content together with the file name. The hash function can be one of the Secure Hash Algorithms, such as SHA-512/256.
Therefore, for file “file201.csv”, the application computed the hash based on SHA512(“201”, filecontent.string()), which is “7EC8E…AAFAA”
1 | { |
Use hash for reducing calls to tangle
The hash is also useful if you want to reduce the data sent to tangle. For example, a data source is generating a small file per second. However, pushing data to tangle in every second can be a performance bottleneck. If the data source pack all files of every 10 minutes into one, assign an ID and compute the hash value of this data trunk, it can still publish integrity data into tangle but with much lower frequency.
Extend it with optional fields
In addition to the above mandatory fields, you can extend the json object by adding more additional fields for fitting your logic.
For example, you can add a field “location” for storing the application name, and “sensorType” of application owner type. These fields will be tightly coupled with these core fields, and stored in the tangle.
1 | { |
Note
“timestamp” is not a mandatory field, as all transactions in Tangle already has a system timestamp that shows when the data was submitted to the tangle. You can add a “package-received-timestamp” field that shows when the original data package was collected.
Step 3. Data source send data integrity information to the channel
Data source sends above json object to the MAM channel (IOTA tangle). The json object will be stored in a MAM address inside of the channel. This can be done by using the demo code shown above.
— At this point, data source completes all needed tasks—-
Step 4. Data consumer obtains the root address of the MAM channel from the data source
Data consumer goes to the website from step 1 to get the root address of the MAM channel that belongs to the data source.
Step 5. Data consumer obtains the wayOfProof and valueOfProof for a specific package
Data consumer goes through the MAM channel, address by address, to find the json object for the specific package, by using packageID. Then it obtains the wayOfProof and valueOfProof for that package.

The pseudo-code is
1 | // get root address of the channel, from data source website |
Step 6. Data consumer prepare for verification
Data consumer read the “wayOfProof” to understand how to check the “valueOfProof” field. For example, compute the hash by using the same hash function “SHA512(201, filecontent.string())” for package 201.
Step 7. Data consumer to verify the integrity
Data consumer compares the hash values from the MAM channel and the local compute process.
- If hash value matches, then integrity is OK, accept the package.
- If hash value does NOT match, then integrity is NOT OK, reject the package.
Deep dive #2: Data Lineage
A case study
Let’s look at a real life case:
You as an American tourist was having an vacation in Norway. You were driving a car and had a great experience of the fjords. Unfortunately you had a small accident outside of a gas station, and the car windshield was damaged (but lucky, no one has been injured). The local police station was informed and issued a form (in Norwegian!) about this accident.
Now you would like to report this to your insurance company.

Most likely the insurance company would like to know if they can trust the damage report. You can of course explain that the data flow is:
- The police station in Norway issued a statement in Norwegian “2018 20. februar 13:00: En liten bilulykke utenfor Esso bensinstasjon på Billingstadsletta 9, 1396 Billingstad. Bilskade: 5000 NOK.”
- Since the US based insurance company only accept documents in English, a translation provider helped to translate this statement from Norwegian to English: “2018 Feb 20th, 13:00PM: A small car accident outside of Esso gas station at Billingstadsletta 9, 1396 Billingstad.Car damage: 5000 NOK. “
- The next step is to convert the currency 5000 NOK to US Dollar, according to the currency rate of 2018 Feb 20th, as well as provide a map for describing the location of the accident. Therefore a currency converter and a geolocation service provider were involved for providing data.

If we can store and verify this flow (data lineage of the report), it will:
- Provide full traceability of the end-to-end process
- Save huge cost from insurance company by reducing the time-consuming manual verification process
- Immutable histories of all inputs of the report. It also helps to identify responsibility of any false input.
Solution Design
On the top of the data integrity layer that we discussed above, it is easy to extend the format to build the data lineage layer.
Now we extend the format to include an optional field “inputs“, which is an array of MAM addresses. These addresses represent the data integrity information of all inputs of the current data package. A MAM address is a global unique identifier in Tangle, regardless of which channel it belongs to.
Extent the format to include inputs
1 | { |
Depends on if you have any input, “inputs“ field is optional. You can ignore this field, or have this field, but the value is null.
The illustration is as below:

Then, for above insurance report case, by using the additional inputs field, it is easy to establish the follow data lineage flow:

It means that
- The insurance company can verify that the report#33 is indeed from the report generator and it was not tampered.
- By following the inputs fields, the insurance company can also find all upstream data and data origin in report#33, and verify the integrity of them as well.
- It also helps, for example, if there is a mistake of the currency convert from NOK to USD, it is the currency converter, not the report generator (customer), that holds the responsibility.
FAQ
Q1: Can I use IOTA and MAM protocol without IOTA token?
A1: Yes. Technically all MAM messages are 0(zero) value transactions. You can create unlimited MAM messages without any IOTA token.
Q2: Can I use IOTA and MAM protocol without hosting an IOTA node?
A1: Yes. You can use public hosted nodes on mainnet. For example, check https://thetangle.org/nodes or google “iota public nodes”. However, for production-ready solutions, having a managed node is recommended, which can offer you, for example, capacity of permanode, see Q3.
Q3: What are Public nodes and Permanode? Which one should I use?
A3: Some explanation can be found at here, for example. The short answer is, if you need to keep the historical MAM messages away from IOTA snapshots, go with permanode. Veracity is planning to host permanode(s) for the platform and its partners/customers.
Q4: Is it free to create a private seed and send messages to MAM channels?
A4: Yes, you can simply create a seed (a string) locally and store data into MAM channel. Feel free to generate seeds for your sensors/applications.
Q5: I do not want to use public MAM channels that anyone can take a look at, even if I know the messages only contain hash values. How can I protect the channels?
A5: MAM channel supports 3 access levels: public, private and restricted. In our solution, in order to make the verification as a self-service, we decided to use public channels. But it is possible to switch to private or restricted channels, and grant access to the selected data consumers to the channel.
Q6: I have an application that is sending out data to consumers. Do I need to do anything if a new consumer starts using my data and build the lineage on top of it?
A6: No. As a data source sitting in the upstream, you do not need to do anything for downstream consumers.
Q7: I am a data consumer. What information do I need to create the whole data lineage covering all inputs in different levels? For example, if the data flow is Alice->Bob->Carol->myself, do I need to know the MAM root address of Alice, Bob and Carol?
A7: No, you only need MAM root of Carol. As far as you follow the input fields recursively,you can check integrity and lineage of Bob (Carol’s upstream) and Alice (Bob’s upstream). In above insurance case, the insurance company can also follow the inputs fields to check, for example, the translator’s message and the Norwegian police station’s message.
Q8: This solution sounds great, but it can take some efforts to build it, such as build the UX for data lineage visualization, API for read/write MAM messages, manage seeds properly, etc. Is there anything we can reuse?
A8: I am glad that you asked. In veracity we are building Data Integrity and Lineage as a Service (DILAAS) to bring down the barriers for both data providers and data consumers. DILAAS offers:
- A cloud service for managing and exchanging data integrity and lineage information between parties.
- Standard HTTP API, without building competence of backend DLT, such as MAM programming. It helps to reduce the development cost and boost the onboard progress.
- Seed/Identity management, for properly managing the seeds/identifies in the secure environment.
- Visualization of data integrity and lineage information.
Summary
In this article, we discussed the detailed design of verification data schema, such as these crucial fields: “datapackageId”, “wayofProof” , “valueOfProof” and “inputs”. We also implemented the solution on the selected DLT: IOTA and its MAM protocol. In next article of this series, we will put this solution into actions, and have closer look at some components of the DILAAS.
Appendix
Masked Authenticated Messaging (MAM) was introduced by IOTA in Nov 2017. The high level description can be found here. In addition, some deep dive information of Tangle transaction and MAM can be found at:
- IOTA: MAM Eloquently Explained
- Javascript lib of MAM: https://github.com/iotaledger/mam.client.js
- MAM deep dive (youtube)
Other articles in this series: