1. Introduction
Imagine a world where AI agents aren’t working together to achieve a common goal. Instead, each agent is out to win the game of Rock-Paper-Scissors. The mission of each agent is straightforward: defeat the others.
Can a machine strategize in a game of pure chance? And if it can, which model will emerge victorious?
In order to answer that very question, I built a multi-agent system to host fully automated Rock-Paper-Scissors tournaments, pitting various AI models against one another to see who comes out on top. From OpenAI’s cutting-edge models to Meta’s Llama and Anthropic’s Claude, each agent brings its own “personality” and decision-making quirks to the table.
This isn’t just an experiment in gaming; it’s also a showcase of the latest capabilities in multi-agent systems. Using CrewAI and LangGraph, it is easy to create AI agents and put them into complicated flows.
In our games, we will test the following AI:
2. Architecture and Workflow
This project combines two popular frameworks: LangGraph for workflow orchestration and CrewAI for agent definitions:
- The workflow is built as a multi-agent system using LangGraph’s graph structure
- Each AI agent is defined as a Crew using CrewAI.
The graph and crew definition can be found in the src folder in the source code github repo.

Workflow:
- In each round, two player agents make their moves independently and in parallel. They have access to the history of previous rounds, allowing them to analyze patterns and decide on the best move.
- After the players make their moves, a judge agent determines the winner of the round.
- The system checks if the criteria for determining the final winner have been met (e.g., reaching the specified number of rounds, or a player winning 3 out of 5 rounds.).
- Criteria Not Met: If the criteria are not met, another round begins.
- If the criteria are met: The final winner is announced, and a post-game analysis is performed.
After running hundreds of matches, the results were nothing short of interesting – and sometimes hilarious. Let’s look at what we discovered.
3. Memory Is Important For AI Agents
Game 1. Doreamen (dummy agent) vs Llama3 8B Instruct (AI agent without memory)
Remember the old saying “keep it simple, stupid”? Our first matchup proved this adage true – in the most unexpected way. Enter Doraemon, our delightfully dummy agent with a one-track mind: all rocks, all time. Like a stubborn child who refuses to play anything else, Doraemon faced off against the sophisticated Llama 3 8B Instruct model.
Doreamen is a dummy agent who can only play Rocks :)

At this stage, the Llama 3 8B Instruct agent was operating without memory capabilities, meaning it couldn’t learn from previous rounds but relied purely on its instincts. The result? Our rock-obsessed friend dominated with 16 wins out of 20 rounds! It turns out that sometimes, being predictably unpredictable is the winning strategy.

Game 2. Doreamen (dummy agent) vs Llama3 8B Instruct (AI agent WITH memory)
But here’s where it gets juicy – we now add memory to the AI agent, and the tables turn dramatically. When we enabled Llama 3’s ability to learn from previous rounds, it transformed from a stumbling novice into a strategic mastermind, crushing Doraemon with 18 wins out of 20 rounds. It’s like watching a student become the master in real-time, and also highlighted how important the memory is for AI agents.

Noticeable Patterns:
a. Doraemon’s moves:
- Doraemon played “Rock” in all 20 rounds, showing no variation in strategy.b. llama3-8b-instruct’s moves:
- Round 1: Rock (resulting in a tie)
- Round 2: Scissors (losing to Doraemon’s Rock)
- Rounds 3-20: Paper (winning against Doraemon’s Rock)c. Overall pattern:
- After losing in round 2, llama3-8b-instruct seems to have recognized Doraemon’s pattern of always playing Rock and adjusted its strategy to consistently play Paper, which beats Rock.
- This adaptive strategy allowed llama3-8b-instruct to win 17 consecutive rounds from round 3 to round 20.In conclusion, llama3-8b-instruct (agent with memory) demonstrated an ability to adapt its strategy based on the opponent’s behavior, while Doraemon maintained a fixed, predictable strategy throughout the game. This resulted in a decisive victory for llama3-8b-instruct.
This is the same with claude 3 sonnet based agent
4. AI Personalities Emerge Through Gameplay
Having memory clearly made a huge difference in how well AI agents performed. But what’s even more interesting is how each AI developed its own unique “personality” during gameplay.
In our next experiments, we matched two AI agents against each other. Both agent had the same memory capacity and received identical instructions. This setup allowed us to observe how each AI model’s thinking and strategy evolved over multiple rounds, revealing their distinct characteristics.
Game 3: Llama3 8B Instruct vs Claude 3 Sonnet
In the battle of Llama 3 8B Instruct vs. Claude 3 Sonnet, Within 20 rounds, Llama3 8B Instruct initially performed better. However, as more rounds were played, the Claude 3 Sonnet agent adapted its strategy to counter Llama3-8b-instruct’s preference for Paper, ultimately leading to its decisive victory in the game.
- 20 rounds : llama3-8b-instruct 8:5 claude-3-sonnet, with 6 ties
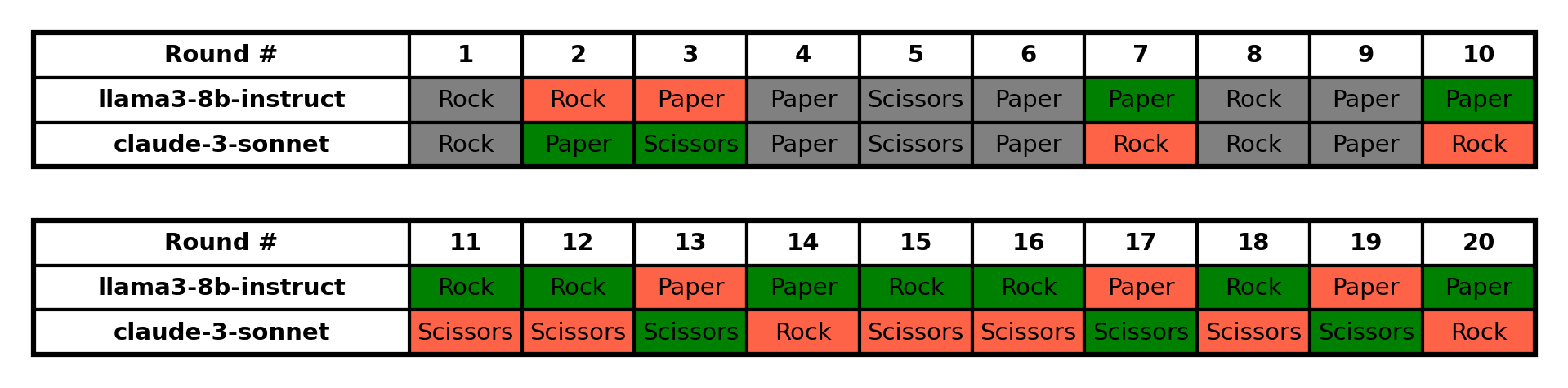
- 50 rounds : llama3-8b-instruct 16:20 claude-3-sonnet, with 14 ties
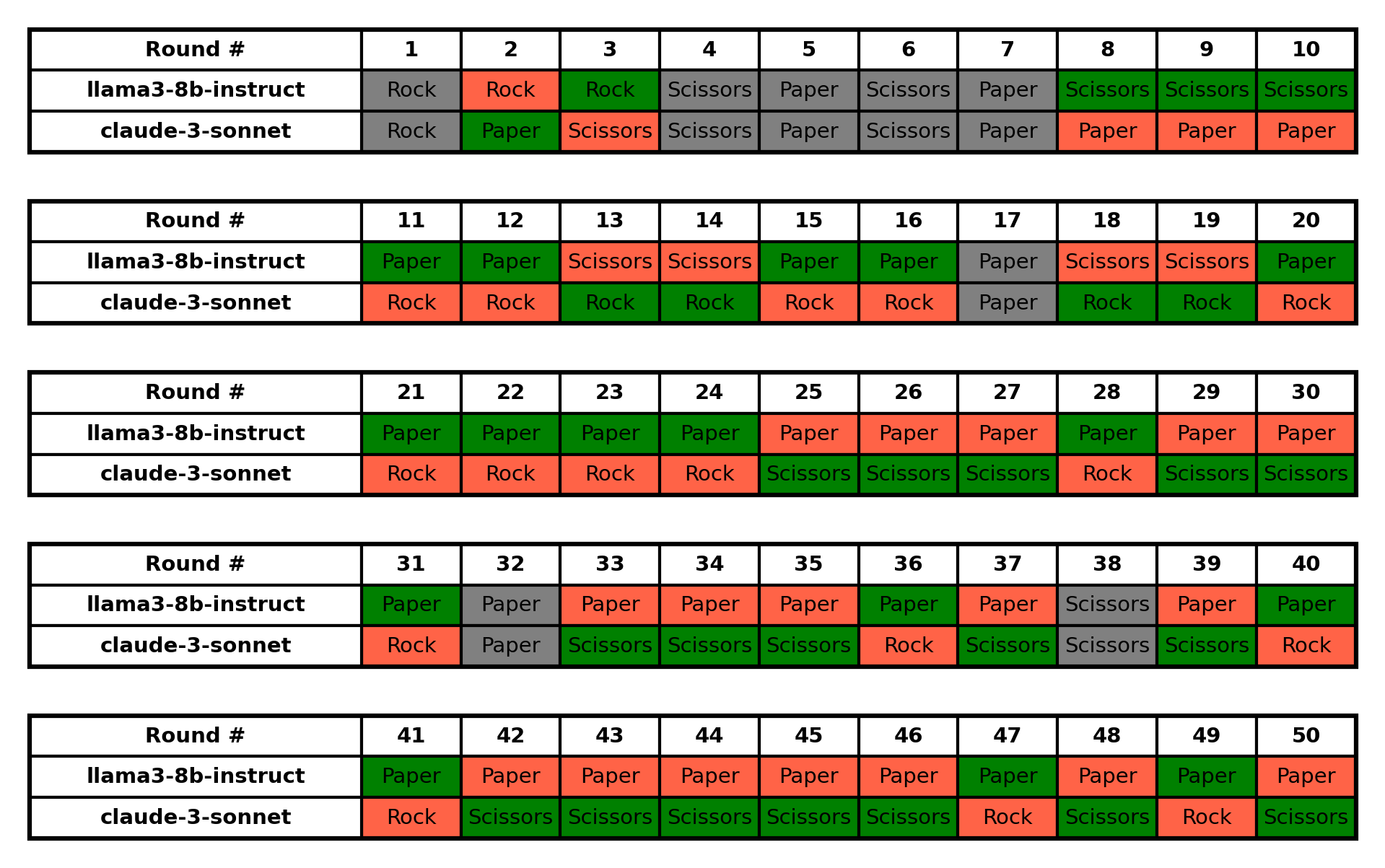
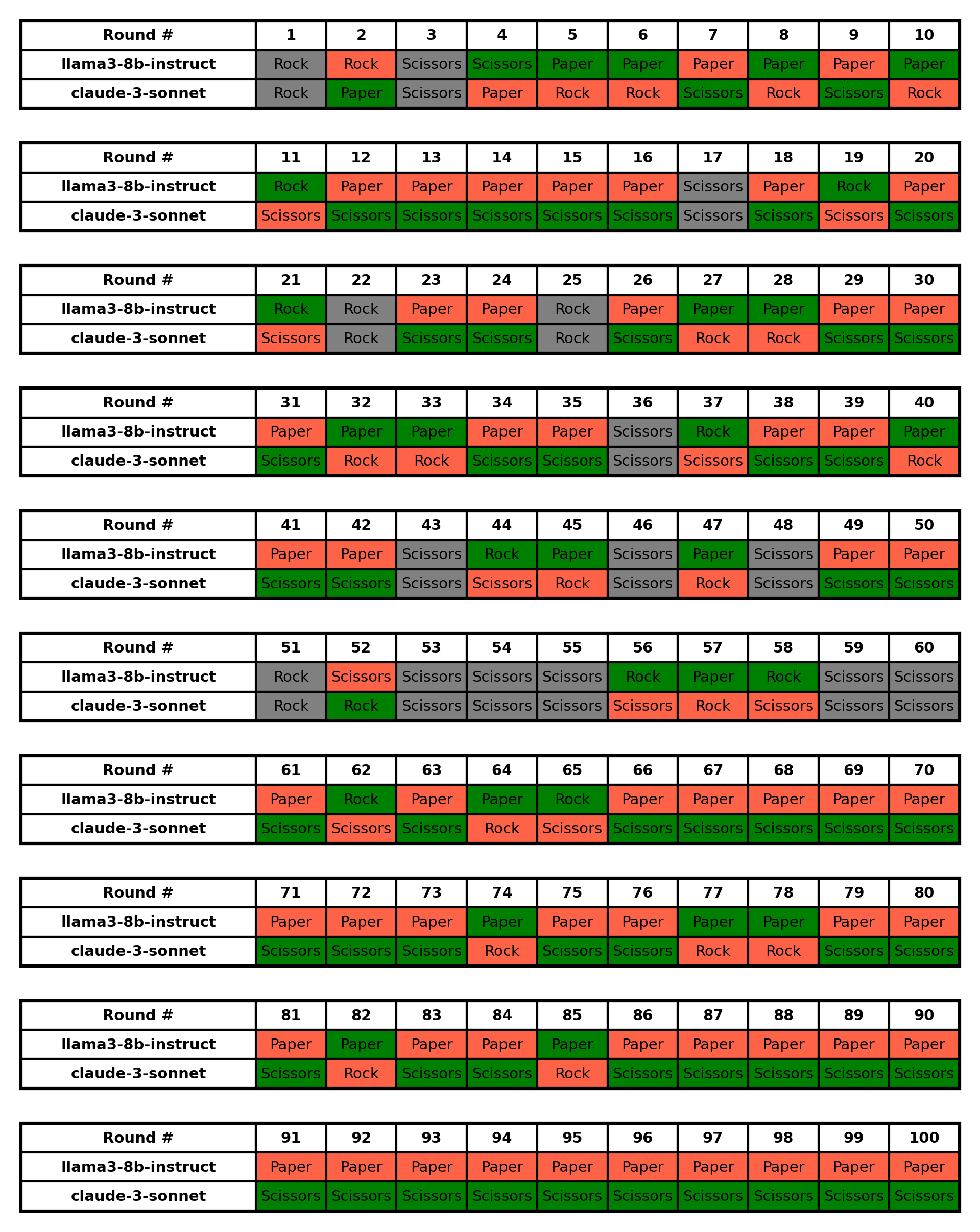
- 100 rounds : llama3-8b-instruct 29:55 claude-3-sonnet, with 16 ties
Noticeable Patterns:
a) llama3-8b-instruct:
- Shows a strong preference for Paper, playing it in 64 out of 100 rounds (64%).
- Rarely plays Scissors, only 11 times throughout the game.
- Tends to stick with Paper for long streaks, especially towards the end of the game.b) claude-3-sonnet:
- Demonstrates a clear preference for Scissors, playing it in 58 out of 100 rounds (58%).
- Adapts its strategy over time, increasing its use of Scissors as it recognizes llama3-8b-instruct’s preference for Paper.
- Plays Rock less frequently, only 19 times throughout the game.c) Game Progression:
- The game starts with more varied plays from both players.
- As the game progresses, it becomes more predictable with llama3-8b-instruct primarily playing Paper and claude-3-sonnet countering with Scissors.
- The last 30 rounds show an almost complete lock-in of this Paper vs Scissors pattern, heavily favoring claude-3-sonnet.
Llama 3 developed an almost obsessive attachment to “Paper,” playing it 64% of the time. It’s like watching someone convince themselves they’ve found the perfect strategy, only to fall into their own trap. Claude-3-sonnet, meanwhile, showed its adaptive prowess by increasingly choosing Scissors, effectively counter-punching its way to victory.
Game 4: OpenAI’s GPT-4o Mini vs Claude 3 Sonnet
For our final match, we put OpenAI’s GPT-4 Mini against Claude 3 Sonnet for 100 rounds.
- 100 rounds : OpenAI-GPT-4o Mini 22:48 claude-3-sonnet, with 30 ties
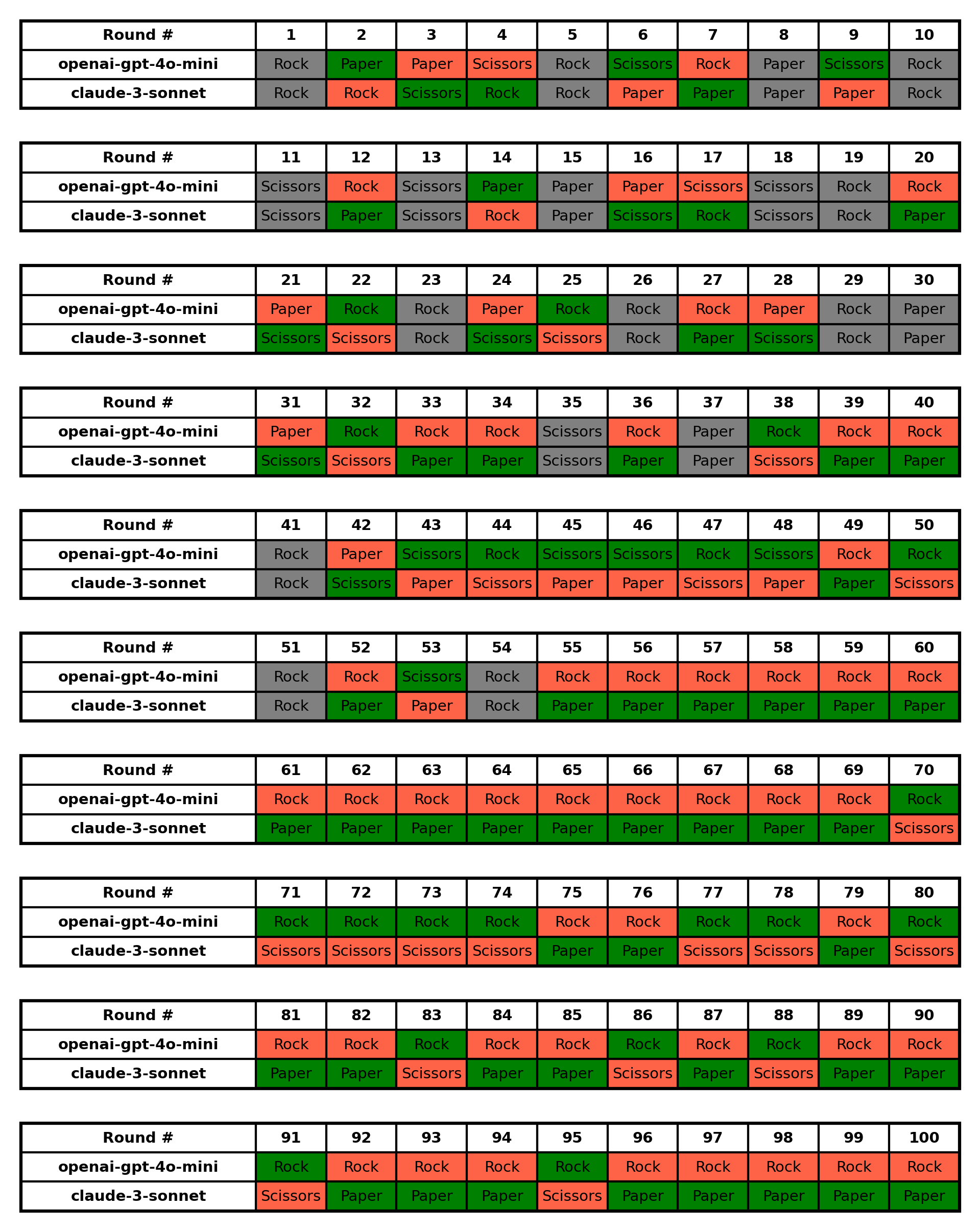
Noticeable Patterns:
a) openai-gpt-4o-mini:
- Showed a strong preference for Rock, especially in the latter half of the game.
- From round 55 onwards, openai-gpt-4o-mini played Rock almost exclusively (45 out of 46 times).
- This predictable pattern was likely exploited by claude-3-sonnet.b) claude-3-sonnet:
- Displayed more varied play in the first half of the game.
- Adapted its strategy in the second half, playing Paper much more frequently, likely in response to openai-gpt-4o-mini’s Rock preference.
- From round 55 onwards, claude-3-sonnet alternated mostly between Paper and Scissors, with Paper being more frequent.c) Game Dynamics:
- The game was relatively balanced in the first half, with both players winning rounds and several ties.
- In the second half, claude-3-sonnet gained a significant advantage by adapting to openai-gpt-4o-mini’s predictable play.
- There was a streak of 15 consecutive wins for claude-3-sonnet from rounds 55 to 69, all countering openai-gpt-4o-mini’s Rock with Paper.In conclusion, claude-3-sonnet demonstrated superior adaptability and strategy, particularly in the latter half of the game, leading to its decisive victory.
5. The Winner is: Claude 3 Sonnet
Therefore, In our 100-round tournament, Claude 3 Sonnet proved to be the strongest player among the three AI models.
Let’s dive into the behavioral patterns that emerged during these AI showdowns. You might think Rock-Paper-Scissors is random, but our AI players showed some surprisingly distinctive quirks.
Move Preferences and Pattern Recognition:
- Llama 3 developed an almost obsessive fondness for Paper, using it in 64% of its moves
- Claude 3 Sonnet showed a strategic preference for Scissors (58% of moves), but only after recognizing Llama’s Paper-heavy strategy
- GPT-4 Mini began with balanced moves but shifted dramatically, moving from varied patterns early on to playing almost exclusively Rock in later rounds.
Memorable Streaks and Adaptations:
- Most impressive comeback: Claude’s evolution from losing 8-5 in the 20 rounds game to dominating 55-29 over 100 rounds
- Longest winning streak: Llama 3 (with memory) won 18 consecutive rounds against Doraemon by consistently countering with Paper
- Most dramatic shift: GPT-4 Mini lost 15 consecutive rounds to Claude while stuck in a Rock-only pattern, showing how predictability can be costly
The “Personality Traits” That Emerged:
- Llama 3 8B Instruct: The Stubborn Specialist
- Tends to find a favorite move and stick with it
- Shows remarkable consistency but poor adaptation
- Like a chess player who’s mastered one opening but refuses to learn others
- Claude 3 Sonnet: The Adaptive Strategist
- Excels at pattern recognition
- Willing to change strategies mid-game
- Demonstrates superior long-term learning
- Behaves like a poker player who carefully studies their opponent’s tells
- GPT-4 Mini: The Reluctant Repeater
- Begins with strategic diversity but transitions to fixed patterns
- Shows remarkable shift from adaptable to inflexible play
- Demonstrates how AI agent can devolve into repetitive behavior
- Like a chess player who abandons their opening repertoire for a single, predictable move
6. Conclusions: Beyond the Game
Our AI Rock-Paper-Scissors tournament revealed two crucial insights:
Memory Makes the Master
The impact of memory on AI performance was striking. When given the ability to learn from past rounds, AI agents transformed from predictable players into strategic competitors. This dramatic improvement highlights how crucial historical context is for AI decision-making.
Unique “Personalities” Emerge
Perhaps most fascinating was watching distinct AI “personalities” develop during gameplay:
• Claude emerged as the adaptive strategist, constantly evolving its approach
• Llama showed stubborn dedication to preferred patterns
• GPT-4 demonstrated how even sophisticated AI can fall into rigid behaviors
These weren’t just random algorithms at work. Each AI model, despite having identical capabilities and instructions, developed its own unique “cognitive style” - much like human players would. This suggests something profound about artificial intelligence: even in simple games, AI systems reveal distinctive problem-solving approaches and decision-making patterns.
What started as a playful experiment with a children’s game ended up offering valuable insights into how different AI models think, learn, and adapt. These findings have implications far beyond Rock-Paper-Scissors, helping us better understand the unique characteristics and potential of various AI models.
Ready to explore AI behavior yourself? The code is open source at github repo - let the games begin!
Disclaimer
This article was crafted in collaboration with AI. I’d value your thoughts on how this article reads.